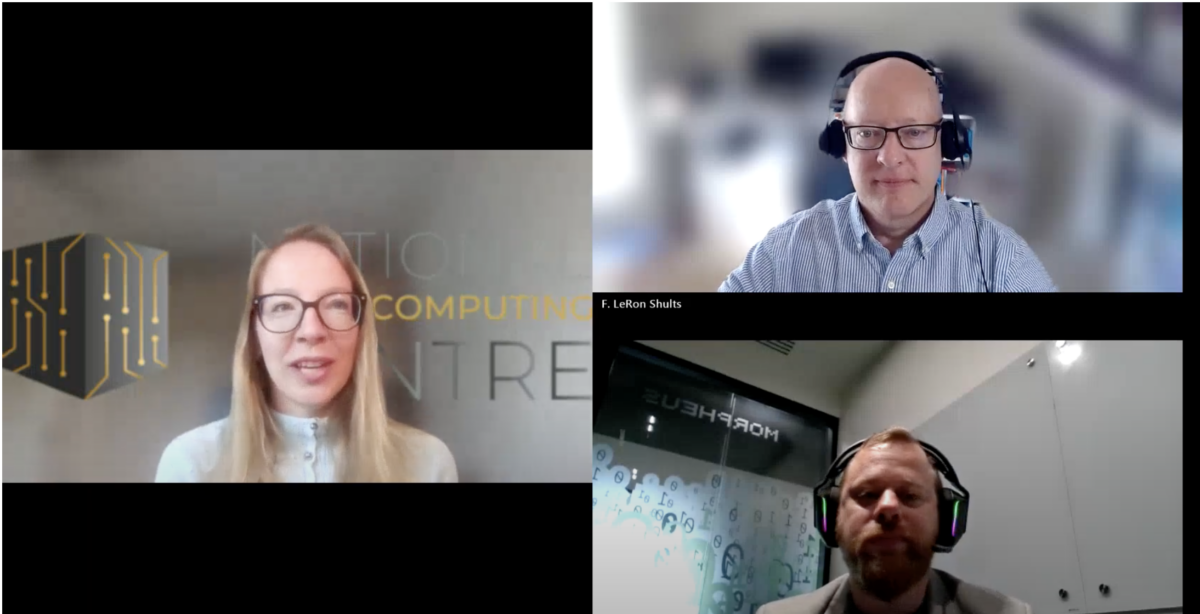
Recording of the Webinar: Simulating Societies through AI and Digital Twins
Did you miss our webinar "Digital Twins of Society: Simulations Powered by HPC”? The recording is now available online. The webinar offered inspiring insights into how artificial intelligence, cognitive modeling, and multi-agent simulation technologies help researchers understand and predict complex social phenomena such as the spread of disinformation, radicalization, and social cohesion.
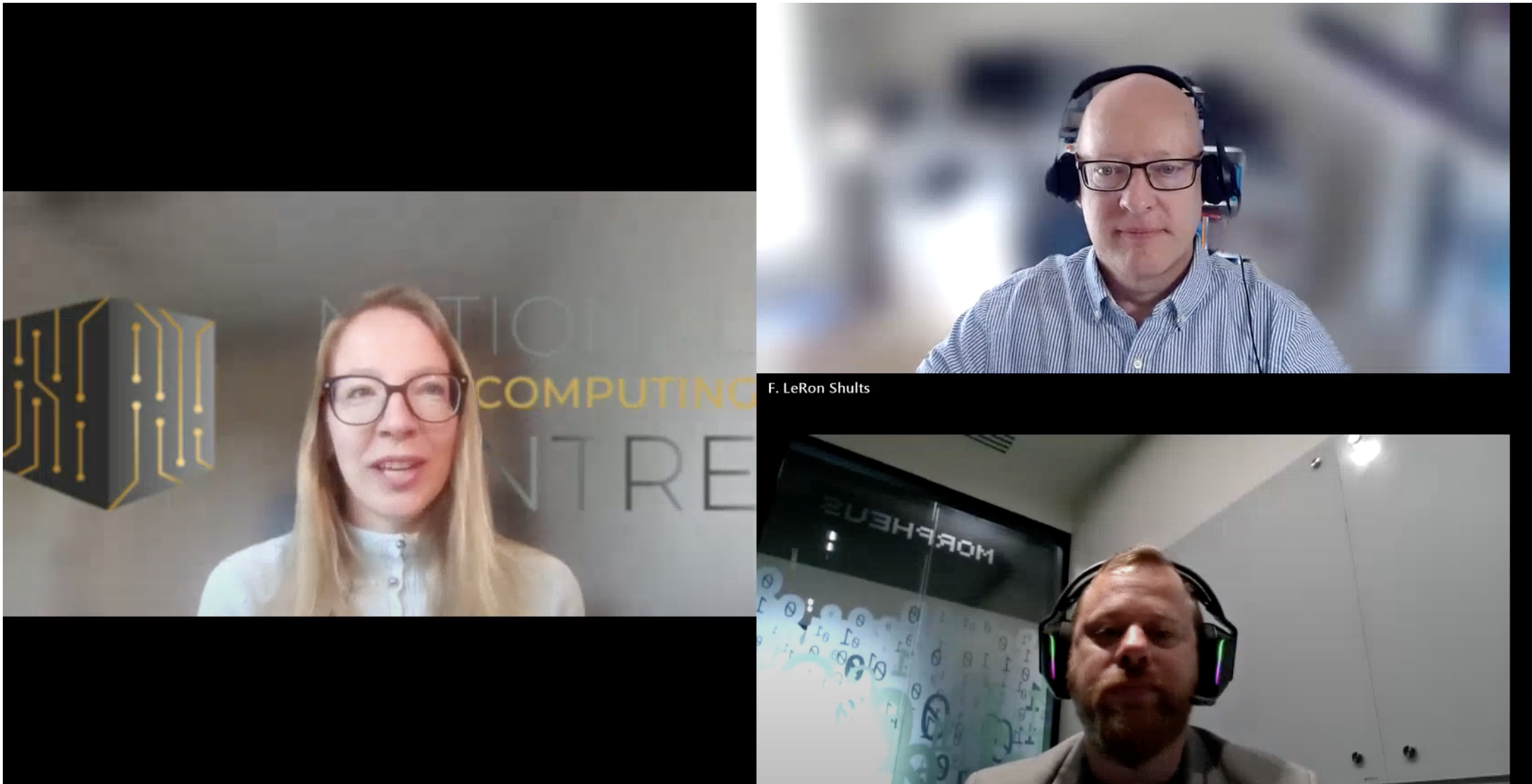
The webinar featured leading experts in the field: Prof. Dr. F. LeRon Shults from NORCE and the University of Agder (Norway), who specializes in cultural cybernetics and modeling extremism, and Dr. Justin Lane, co-founder of CulturePulse AI and Scientific Director of the DEKK Institute, a pioneer in multi-agent AI and the creator of societal digital twins.
The webinar showcased real-world applications of these technologies, including simulations developed for the United Nations, the Norwegian government, and conflict modeling such as the Israel–Palestine crisis. It also introduced the Slovak Digital Twin initiative, which leverages the Devana supercomputer to run large-scale national simulations.
The program also included a discussion on the ethical aspects of using AI and the opportunities for international collaboration.
The webinar was organized by the National Supercomputing Centre Slovakia in collaboration with NCC Norway and NCC Portugal as part of the EuroCC project activities.
 Artificial Intelligence and a Supercomputer as a New Weapon Against Environmental Disasters 26 Mar - Scientists from Nitra, Slovakia are teaching machines to predict industrial failures before they can cause damage. Thanks to collaboration with the European supercomputer LUMI, they have developed a digital “guardian” capable of detecting pipeline leaks or manufacturing faults with high accuracy—helping protect both the environment and companies’ budgets.
Artificial Intelligence and a Supercomputer as a New Weapon Against Environmental Disasters 26 Mar - Scientists from Nitra, Slovakia are teaching machines to predict industrial failures before they can cause damage. Thanks to collaboration with the European supercomputer LUMI, they have developed a digital “guardian” capable of detecting pipeline leaks or manufacturing faults with high accuracy—helping protect both the environment and companies’ budgets. The Slovak Recipe for Fair Play and Happier Players 25 Mar - Do you play games on your phone and sometimes feel like the game just doesn’t understand you? Experts from Nitra, Slovakia, have used one of Europe’s most powerful supercomputers to change that. Thanks to the Italian giant named Leonardo, they discovered how to read between the lines of player behavior and make the gaming experience more personal and fair.
The Slovak Recipe for Fair Play and Happier Players 25 Mar - Do you play games on your phone and sometimes feel like the game just doesn’t understand you? Experts from Nitra, Slovakia, have used one of Europe’s most powerful supercomputers to change that. Thanks to the Italian giant named Leonardo, they discovered how to read between the lines of player behavior and make the gaming experience more personal and fair. Apply for the EUMaster4HPC Summer School 2026 focused on High-Performance Computing. 23 Mar - From 5 to 14 July 2026, the EUMaster4HPC Summer School titled “High-Performance Computing and Emerging Trends” will take place in Luxembourg. The event will be held at the Marienthal Youth Center and the University of Luxembourg in Belval.
Apply for the EUMaster4HPC Summer School 2026 focused on High-Performance Computing. 23 Mar - From 5 to 14 July 2026, the EUMaster4HPC Summer School titled “High-Performance Computing and Emerging Trends” will take place in Luxembourg. The event will be held at the Marienthal Youth Center and the University of Luxembourg in Belval.




















