Devana: Výzva na podávanie projektov pre štandardný prístup k HPC 1/25
Výzva na podávanie projektov pre štandardný prístup k HPC 1/25 je otvorená. Projekty je možné podávať v rámci otvorených výziev 3 krát do roka. O prístup je možné požiadať výhradne prostredníctvom používateľského portálu register.nscc.sk.
Štandardný prístup k vysokovýkonným výpočtovým prostriedkom je otvorený pre všetky oblasti vedy a výskumu a to predovšetkým pre projekty väčšieho rozsahu. Tieto projekty by mali preukázať excelentnosť v danej oblasti a jasný potenciál priniesť inovatívne riešenia súčasných spoločenských a technologických výziev. V žiadosti je potrebné demonštrovať efektívnosť a škálovateľnosť navrhovaných výpočtových postupov a metód v HPC prostredí. Potrebné dáta o výkone a parametroch zvažovaných algoritmov a aplikácií je možné získať v rámci Prístupu pre testovanie a benchmarking.
Alokácie sa udeľujú na jeden (1) rok s možnosťou požiadať o pokračovanie, ak je to potrebné. Prístup je bezplatný za predpokladu splnenia všetkých náležitostí definovaných v Podmienkach výzvy. Podané projekty vyhodnocuje po technickej stránke interný tím VS SAV a NSCC a kvalitu vedecko-výskumnej časti hodnotia vždy dvaja nezávislí externí hodnotitelia.
Call opening date: 8.1.2025 Call closing date: 7.2. 2025, 17:00 CET Communication of allocation decision: Up to 2 weeks from Call closing. Start of the allocation perion for awarded projects: najneskôr 24. 2. 2025
Eligible Researchers O štandardný prístup k HPC môžu žiadať vedci a výskumníci zo slovenských verejných vysokých škôl a Slovenskej akadémie vied, ako aj z organizácií verejnej a štátnej správy. Prístup je poskytovaný výhradne pre civilný a nekomerčný open-science výskum a vývoj. Záujemcovia zo súkromných spoločností môžu využiť služby Hopero from HealthHub.
Final report within 2 months from the end of the project.
Peer-review and other publications in domestic and foreign scientific periodicals with acknowledgments in the pre-defined wording, reported through the user portal.
Active participation in the Slovak HPC conference organized by the coordinator of this call (poster, other contribution).
Participation in dissemination activities of the coordinator (interview, article in the HPC magazine, etc.).
Dňa 14. novembra 2024 sa v hoteli Devín v Bratislave uskutočnila odborná konferencia s názvom Superpočítač a Slovensko, ktorú zorganizovalo Ministerstvo investícií, regionálneho rozvoja a informatizácie SR. Konferencia sa zameriavala na aktuálne trendy a vývoj v oblasti vysokorýchlostného počítania na Slovensku. Súčasťou podujatia bola prezentácia L. Demovičovej z Národného kompetenčného centra pre HPC.
Vo svojej prezentácii predstavila projekt kompetenčného centra pre HPC, ktoré pomáha firmám a inštitúciám využívať výkonné výpočtové kapacity na riešenie náročných úloh v oblasti výskumu a vývoja. Počas vystúpenia tiež priblížila niekoľko úspešných prípadových štúdií, na ktorých NCC spolupracovalo s rôznymi firmami. Tieto projekty ukázali, ako môže využitie superpočítačov a výpočtových klastrov zrýchliť a zefektívniť inovácie a vývoj produktov v rôznych odvetviach.
Program konferencie zahŕňal pestrú škálu vystúpení odborníkov z oblasti vysokovýkonného počítania (HPC). Úvodné slovo patrilo hlavným organizátorom, ktorí predstavili význam konferencie a aktuálnu situáciu v oblasti superpočítačov na Slovensku. Nasledovala séria odborných prednášok, ktoré pokryli rôzne témy ako napríklad Vývoj a konštrukcia superpočítača Devana. Prednáška predstavila technické aspekty a architektúru superpočítača.
Súčasťou podujatia bola aj panelová diskusia. Odborníci diskutovali o budúcnosti superpočítačov na Slovensku, ich potenciáli pre akademický a súkromný sektor a možnostiach financovania nových projektov.
Účastníci konferencie mali možnosť diskutovať, zúčastniť sa na odborných prednáškach a nadviazať nové kontakty, čím konferencia významne prispela k šíreniu poznatkov a podpore rozvoja inovatívnych výskumných projektov na Slovensku.
The 4th High-Performance Computing Meeting 2024 held on November 5-6 at the University of Beira Interior in Covilhã, has established itself as a key gathering for users, technicians, and partners of the high-performance computing ecosystem in Portugal. Organized by the National High-Performance Computing Network (RNCA) and FCCN the digital services unit of the Foundation for Science and Technology FCT), the event focused on fostering new collaboration opportunities and advancing digitalization with a significant impact on science and industry. The event opened with workshops offering a hands-on perspective on topics such as submitting European applications and demonstrating the Deucalion supercomputer, highlighting practical HPC applications within the European context. The first day featured addresses by institutional leaders, including representatives from the Foundation for Science and Technology (FCT), who outlined developments and future ambitions in computing in Portugal.
Panels on European HPC infrastructure resources, such as MareNostrum 5 and EuroHPC offerings, emphasized European integration in high-performance computing. The second day delivered technical and practical presentations, focusing on subjects like software transfer from X86 to ARM architectures and the use of containers for AI applications. Participants also explored impactful projects, such as DeepNeuronic, which applies machine learning for security camera systems, and initiatives like the Virtual HPCvLab, broadening their knowledge of new HPC applications.
The event also featured interactions with other competence centers as part of the EuroCC2 project, demonstrating the power of international collaboration to accelerate progress and innovation in high-performance computing. NCC Slovakia’s participation affirmed its commitment to knowledge sharing, exchanging best practices, and supporting projects that utilize high-performance computing. During the meeting, we also explored opportunities for collaboration in training and educational activities, further strengthening our international ties and contributing to the development of HPC competencies.
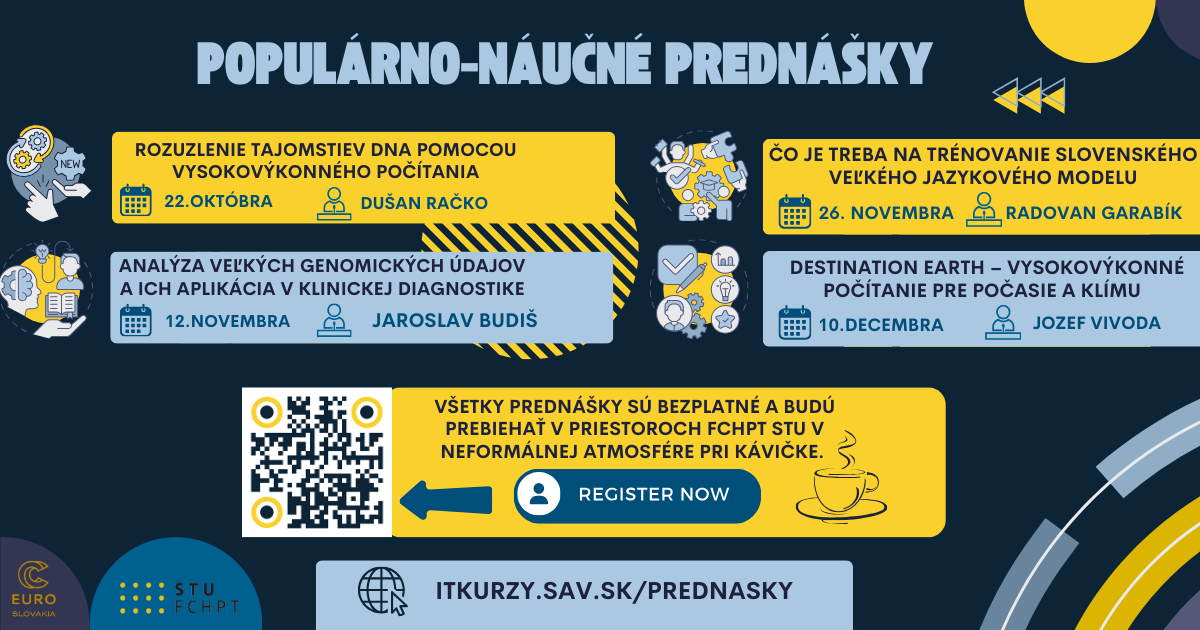
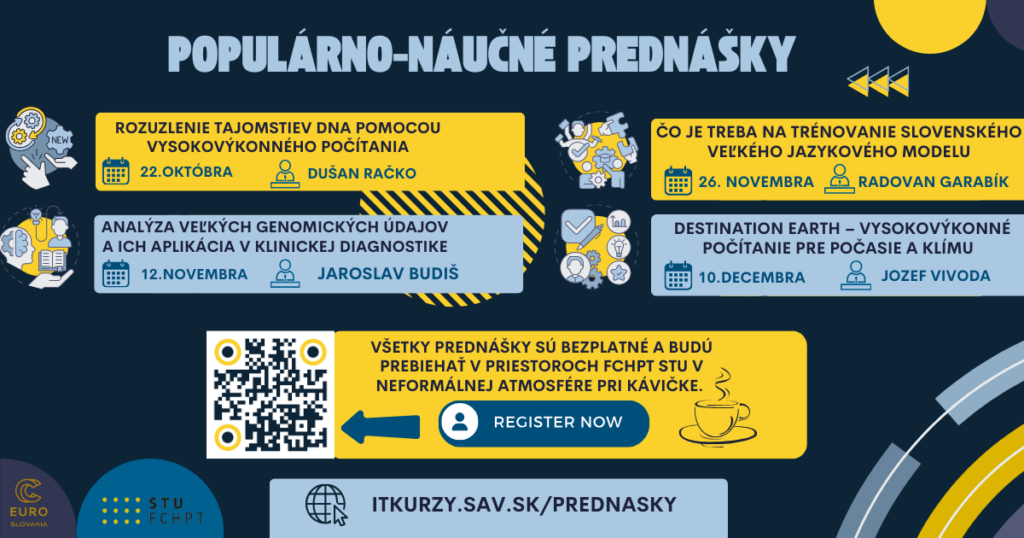
Otvorili sme registráciu na sériu prednášok v zimnom semestri 2024, kde sa budeme venovať fascinujúcim témam, v ktorých vysokovýkonné počítanie zohráva kľúčovú úlohu. Tento semester sa zameriame na oblasti ako meteorológia, klimatológia, chémia, veľké jazykové modely a mnoho ďalších.
Prednášky budú pokrývať širokú škálu tém, vrátane využitia HPC a umelej inteligencie v tvorbe klimatických modelov, diskusií o genetickom sekvenovaní, počítačových simuláciách polymérov, DNA a topologických molekúl. Taktiež sa budeme venovať genomickým analýzam, ktoré majú významný presah do biomedicíny, zdravotníctva a epidemiológie. Zaujímavou témou bude aj otázka, či v slovenskom jazyku existuje dostatok slov na trénovanie veľkých jazykových modelov.
Zoznam prednášok:
Unraveling the Mysteries of DNA Using High-Performance Computing (Dušan Račko)
Účastníci budú mať možnosť diskutovať s pozvanými expertmi po prednáškach, ktoré sa budú konať prezenčne v budove FCHPT STU na Radlinského 9 v Bratislave alebo online cez Zoom. Záznamy prednášok budú dostupné na YouTube. Ak máte záujem o konkrétnu tému alebo by ste chceli prezentovať vlastný výskum, contact us.!
After a long time, the Slovak AI community got a new, this time a really big language model for the Slovak language. Almost three years after the release of the first Slovak language model, SlovakBERT, the collective of authors formed by Peter Bednár from the Department of Cybernetics and Artificial Intelligence FEI TUKE, Marek Dobeš from the Center for Social and Psychological Sciences SAV and Radovan Garabík from the Ľudovít Štúr Institute of Linguistics SAV used the Mistral multilingual model as a basis -7B-v0.1 with seven billion parameters.
Data from the web corpus "Araneum Slovacum VII Maximum" were used for fine-tuning of all parameters. As the authors state, if necessary, the quality of the pre-trained model can be improved by further training on a specific problem. At the same time, they point out that the model does not contain any moderating mechanism.
The training of the Mistral-sk-7b model was carried out on the currently seventh most powerful supercomputer in the world, Leonardo, procured by the consortium of the same name, of which Slovakia is also a member. The authors obtained the necessary computing time thanks to a successful project within the national challenge for access to the Leonardo supercomputer, which was coordinated by the Computing Center of the Slovak Academy of Sciences in cooperation with the National Supercomputer Center.
Model Mistral-sk-7b is published under the license "Apache 2.0" on the platform Hugging Face, under the organization "Slovak NLP Community"
NCC for HPC at INOFEST 2024: Innovation Festival in Žilina
On September 17 and 18, 2024, the fifth edition of the innovation festival INOFEST 2024 organized by the INOVATO association, took place in Žilina. The event became a unique platform for the meeting of experts, entrepreneurs, academics, innovators, students, representatives of the state administration and the public, thereby strengthening cooperation in the field of regional innovation ecosystems in Slovakia.
More than 200 participants attended the two-day program, which included lectures, workshops, discussions and networking. The main goal of the event was to contribute to the connection of companies and other actors at the national level, while creating new business opportunities and inspiration for solving current challenges in the business and social environment.
The first day's program focused on key topics such as automation, robotics, space industry and sustainable solutions. Experts such as František Duchoň from the National Robotics Center spoke at the conference, who talked about Slovakia's progress in the field of robotics, and Michaela Musilová, an astrobiologist and astronaut, who presented the possibilities of how space technologies can improve life on Earth.
A leading place also belonged to the topics of sustainability, circular economy and modularity, where, for example, Stanislav Martinec from KOMA Modular spoke about how modular construction can contribute to a sustainable future. During the first day of INOFEST 2024, a significant part of the program was devoted to the topic of artificial intelligence under the title "Artificial intelligence as the topic of 2024". In his presentation, Libor Bešényi from XOLUTION ROBOTS focused on the implementation of AI in businesses and drew attention to the difference between effective and unnecessary deployment of AI. Martin Jančura from ITRANSYS explained that not all AI is the same and understanding it correctly is key to success. Martin Haranta from PERBIOTIX pointed out how AI can help even small companies achieve great success. Mária Bieliková from KInIT spoke about the potential of AI to transform Slovakia in the field of business and the public sector. The block ended with Vladimír Šucha, representative of the European Commission in Slovakia, with the presentation "Artificial intelligence in action: Catalyst of changes in the economy and society". Šucha emphasized that AI is not only a technological tool, but also a catalyst for fundamental changes in the economy, education and public services, which can fundamentally affect the future of Slovakia and Europe. The evening was characterized by innovations and a social program, including a musical performance by Tomáš Bezdeda and the ceremonial presentation of the innovation award.
The second day of the festival was dedicated to inspiration from business, where successful entrepreneurs such as Artur Gevorkyan and Ľubomír Klieštik presented their stories. The conversation with Michaela Musilová attracted the attention of the younger generation in particular, as she shared her experiences from scientific missions and simulations of life on Mars.
The INOFEST 2024 program also included a special workshop attended by the National Competence Center for High Performance Computing (HPC). Lucia Demovičová presented the competence center project, which helps companies and institutions use powerful computing capacities to solve demanding tasks in the field of research and development.
During his presentation, Michal Pitonák presented several successful case studiessuccess storieson which NCC collaborated with various companies. These projects have shown how the use of supercomputers and computing clusters can accelerate and streamline innovation and product development in various industries.
In addition to the main program, participants had the opportunity to take part in side events, including an exhibition of innovative technologies, robotics workshops and discussions on the future of electromobility. One of the highlights of the festival was the presentation of financing options for innovative projects, where experts provided an overview of available resources, including European funds and the Horizon Europe program.
INOFEST 2024 in Žilina once again proved that Slovakia is a country where innovation, cooperation and new technologies have their place and that such a festival can be a great opportunity for building relationships, inspiration and growth in the field of innovation.
INOFEST 2024Halyna Hyryavets (National Competence Centre for High-performacne Computing)Lucia Demovičová (National Competence Centre for High-performacne Computing)EuroCC Slovakia Slovak National Competence Centre for High-performance ComputingMichal Pitoňák (Slovak National Competence Centre for High-performance Computing)Lucia Demovčiová and Michal Pitoňák (Inofest 2024)ŽilinaEuroCC Slovakia
Intent Classification for Bank Chatbots through LLM Fine-Tuning
This study evaluates the application of large language models (LLMs) for intent classification within a chatbot with predetermined responses designed for banking industry websites. Specifically, the research examines the effectiveness of fine-tuning SlovakBERT compared to employing multilingual generative models, such as Llama 8b instruct from Gemma 7b instructin both their pre-trained and fine-tuned versions. The findings indicate that SlovakBERT outperforms the other models in terms of in-scope accuracy and out-of-scope false positive rate, establishing it as the benchmark for this application.
The advent of digital technologies has significantly influenced customer service methodologies, with a notable shift towards integrating chatbots for handling customer support inquiries. This trend is primarily observed on business websites, where chatbots serve to facilitate customer queries pertinent to the business’s domain. These virtual assistants are instrumental in providing essential information to customers, thereby reducing the workload traditionally managed by human customer support agents.
In the realm of chatbot development, recent years have witnessed a surge in the employment of generative artificial intelligence technologies to craft customized responses. Despite this technological advancement, certain enterprises continue to favor a more structured approach to chatbot interactions. In this perspective, the content of responses is predetermined rather than generated on-the-fly, ensuring accuracy of information and adherence to the business’s branding style. The deployment of these chatbots typically involves defining specific classifications known as intents. Each intent correlates with a particular customer inquiry, guiding the chatbot to deliver an appropriate response. Consequently, a pivotal challenge within this system lies in accurately identifying the user’s intent based on their textual input to the chatbot.
Problem Description and Our Approach
This work is a joint effort of Slovak National Competence Center for High-Performance Computing and nettle, s.r.o., which is a Slovakia-based start-up focusing on natural language processing, chatbots, and voicebots. HPC resources of Devana system were utilized to handle the extensive computations required for fine-tuning LLMs. The goal is to develop a chatbot designed for an online banking service.
In frameworks as described in the introduction, a predetermined precise response is usually preferred over a generated one. Therefore, the initial development step is the identification of a domain-specific collection of intents crucial for the chatbot’s operation and the formulation of corresponding responses for each intent. These chatbots are often highly sophisticated, encompassing a broad spectrum of a few hundreds of distinct intents. For every intent, developers craft various exemplary phrases that they anticipate users would articulate when inquiring about that specific intent. These phrases are pivotal in defining each intent and serve as foundational training material for the intent classification algorithm.
Our baseline proprietary intent classification model, which does not leverage any deep learning framework, achieves a 67% accuracy on a real-world test dataset described in the next section. The aim of this work is to develop an intent classification model using deep learning, that will outperform this baseline model.
We present two different approaches for solving this task. The first one explores the application of Bidirectional Encoder Representations from Transformers (BERT), evaluating its effectiveness as the backbone for intent classification and its capacity to power precise response generation in chatbots. The second approach employs generative large language models (LLMs) with prompt engineering to identify the appropriate intent with and without fine-tuning the selected model.
Dataset
Our training dataset consists of pairs (text, intent), wherein each text is an example query posed to the chatbot, that triggers the respective intent. This dataset is meticulously curated to cover the entire spectrum of predefined intents, ensuring a sufficient volume of textual examples for each category.
In our study, we have access to a comprehensive set of intents, each accompanied by corresponding user query examples. We consider two sets of training data: a “simple” set, providing 10 to 20 examples for each intent, and a “generated” set, which encompasses 20 to 500 examples per intent, introducing a greater volume of data albeit with increased repetition of phrases within individual intents.
These compilations of data are primed for ingestion by supervised classification models. This process involves translating the set of intents into numerical labels and associating each text example with its corresponding label, followed by the actual model training.
Additionally, we utilize a test dataset comprising approximately 300 (text, intent) pairs extracted from an operational deployment of the chatbot, offering an authentic representation of real-world user interactions. All texts within this dataset are tagged with an intent by human annotators. This dataset is used for performance evaluation of our intent classification models by feeding them the text inputs and comparing the predicted intents with those annotated by humans.
All of these datasets are proprietary to nettle, s.r.o., so they cannot be discussed in more detail here.
Evaluation Process
In this article, the models are primarily evaluated based on their in-scope accuracy using a real-world test dataset comprising 300 samples. Each of these samples belongs to the in-scope intents on which the models were trained. Accuracy is calculated as the ratio of correctly classified samples to the total number of samples. For models that also provide a probability output, such as BERT, a sample is considered correctly classified only if its confidence score exceeds a specified threshold. Throughout this article, accuracy refers to this in-scope accuracy.
As a secondary metric, the models are assessed on their out-of-scope false positive rate, where a lower rate is preferable. For this evaluation, we use artificially generated out-of-scope utterances.
The model is expected either to produce a low confidence score below the threshold (for BERT) or generate an ’invalid’ label (for LLM, as detailed in their respective sections).
Since the data at hand is in the Slovak language, the choice of a model with Slovak understanding was inevitable. Therefore, we have opted for a model named SlovakBERT [5], which is the first publicly available large-scale Slovak masked language model.
Multiple experiments were undertaken by fine-tuning this model before arriving at the top-performing model. These trials included adjustments to hyperparameters, various text preprocessing techniques, and, most importantly, the choice of training data.
Given the presence of two training datasets with relevant intents (“simple” and “generated”), experiments with different ratios of samples from these datasets were conducted. The results showed that the optimal performance of the model is achieved when training on the “generated” dataset.
After the optimal dataset was chosen, further experiments were carried out, focusing on selecting the right preprocessing for the dataset. The following options were tested:
turning text to lowercase,
removing diacritics from text, and
removing punctuation from text.
Additionally, combinations of these three options were tested as well. Given that the leveraged SlovakBERT model is case-sensitive and diacritic-sensitive, all of these text transformations impact the overall performance.
Findings from the experiments revealed that the best results are obtained when the text is lowercased and both diacritics and punctuation are removed.
Another aspect investigated during the experimentation phase was the selection of layers for fine-tuning. Options to fine-tune only one quarter, one half, three quarters of the layers, and the whole model were analyzed (with variations including fine-tuning the whole model for the first few epochs and then a selected number of layers further until convergence). The outcome showed that the average improvement achieved by these adjustments to the model’s training process is statistically insignificant. Since there is a desire to keep the pipeline as simple as possible, these alterations did not take place in the final pipeline.
Every experiment trial underwent assessment three to five times to ensure statistical robustness in considering the results.
The best model produced from these experiments had an average accuracy of 77.2% with a standard deviation of 0.012.
Banking-Tailored BERT
Given that our data contains particular banking industry nomenclature, we opted to utilize a BERT model fine-tuned specifically for the banking and finance sector. However, since this model exclusively understands the English language, the data had to be translated accordingly.
For the translation, DeepL API[1]was employed. Firstly, training, validation, and test data was translated. Due to the nature of the English language and translation, no further correction (preprocessing) was done to the text, as discussed in 2.3.1Subsequently, the model’s weights were fine-tuned to enhance performance.
The fine-tuned model demonstrated promising initial results, with accuracy slightly exceeding 70%. Unfortunately, further training and hyperparameter tuning did not yield better results. Other English models were tested as well, but all of them produced similar results. Using a customized English model proved insufficient to achieve superior results, primarily due to translation errors. The translation contained inaccuracies caused by the ’noisiness’ of the data, especially within the test dataset.
Approach 2: LLMs for Intent Classification
As mentioned in Section 2in addition to fine-tuning SlovakBERT model and other BERT-based models, the use of generative LLMs for the intent classification was explored too. Specifically, instruct models were selected for their proficiency in handling instruction prompts and question-answering tasks.
Since there are not open-source instruct model exclusively trained for the Slovak language, several multilingual models were selected: Gemma 7b instruct [6] a Llama3 8b instruct For comparison, we also include results for the closed-source OpenAI’s gpt-3.5-turbomodel under the same conditions.
Similarly to [4], we use LLM prompts with intent names and descriptions to perform zero-shot prediction. The output is expected to be the correct intent label. Since the full set of intents with their descriptions would inflate the prompt too much, we use our baseline model to select only top 3 intents. Hence the prompt data for these models was created as follows:
Each prompt includes a sentence (user’s question) in Slovak, four intent options with descriptions, and an instruction to select the most appropriate option. The first three intent options are the ones selected by the baseline model, which has a Top-3 recall of 87%. The last option is always ‘invalid’ and should be selected when neither of the first three matches the user’s question or the input intent is out-of-scope. Consequently, the highest attainable in-scope accuracy in this setting is 87%.
Pre-trained LLM Implementation
Initially, a pre-trained LLM implementation was utilized, meaning a given instruct model was leveraged without fine-tuning on our dataset. A prompt was passed to the model in the user’s role, and the model generated an assistant’s response.
To improve the results, prompt engineering was employed too. It included subtle rephrasing of the instruction; instructing the model to answer only with the intent name, or with the number/letter of the correct option; or placing the instruction in the system’s role while the sentence and options were in the user’s role.
Despite these efforts, this approach did not yield better results than SlovakBERT’s fine-tuning. However, it helped us identify the most effective prompt formats for fine-tuning of these instruct models. Also, these steps were crucial in understanding the models’ behaviour and response pattern, which we leveraged in fine-tuning strategies of these models.
LLM Optimization through Fine-Tuning
The prompts that the pre-trained models reacted best to were used for fine-tuning of these models. Given that LLMs do not require extensive fine-tuning datasets, we utilized our “simple” dataset as detailed in section 2.1The model was then fine-tuned to respond to the specified prompts with the appropriate label names.
Due to the size of the chosen models, parameter efficient training (PEFT) [2] strategy was employed to handle the memory and time issues. PEFT updates only a subset of parameters, while “freezing” the rest, therefore reducing the number of trainable parameters. Specifically, the Low-Rank Adaptation (LoRA) [3] approach was used.
To optimize performance, various hyperparameters were tuned too, including learning rate, batch size, lora alpha parameter of the LoRA configuration, the number of gradient accumulation steps, and chat template formulation.
Optimizing language models involves high computational demands, necessitating the use of HPC resources to achieve the desired performance and efficiency. The Devana system, with each node containing 4 NVidia A100 GPUs with 40GB of memory each, offers significant computational power. In our case, both models we are fine-tuning fit within the memory of one GPU (full size, not quantized) with a maximum batch size of 2.
Although leveraging all 4 GPUs in a node would reduce training time and allow for a larger overall batch size (while maintaining the same batch size per device), for benchmarking purposes and to guarantee consistency and comparability of the results, we conducted all experiments using 1 GPU only.
These efforts led to some improvements in models’ performances. Particularly for Gemma 7b instruct instruct in reducing the number of false positives. On the other hand, while fine-tuning Llama3 8b instruct, both metrics (accuracy and the number of false positives) were improved. However, neither Gemma 7b instruct nor Llama3 8b instruct models outperformed the capabilities of the fine-tuned SlovakBERT model.
With Gemma 7b instructsome sets of hyperparameters resulted in high accuracy but also a high false positive rate, while others led to lower accuracy and low false positive rate. Search for a set of hyperparameters bringing balanced accuracy and false positive rate was challenging. The best-performing configuration achieved an accuracy slightly over 70% with a false positive rate of 4.6%. Compared to the model’s performance without fine-tuning, fine-tuning only slightly increased the accuracy, but dramatically reduced the false positive rate by almost 70%.
With Llama3 8b instruct, the best-performing configuration achieved an accuracy of 75.1% with a false positive rate of 7.0%. Compared to the model’s performance without fine-tuning, fine-tuning significantly increased the accuracy and also halved the false positive rate.
Comparison with a Closed-Source Model
To benchmark our approach against a leading closed-source LLM, we conducted experiments using gpt-3.5-turbo OpenAI.[1]We employed identical prompt data for a fair comparison and tested both the pre-trained and fine-tuned versions of this model. Without fine-tuning, gpt-3.5-turbo achieved an accuracy of 76%, although it exhibited a considerable false positive rate. After fine-tuning, the accuracy improved to almost 80%, and the false positive rate was considerably reduced.
Results
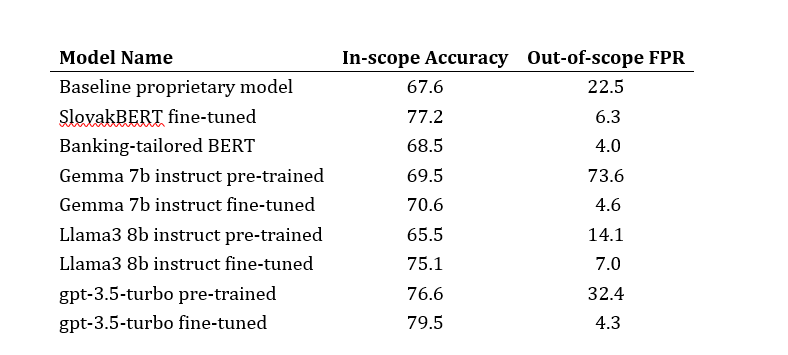
In our initial strategy, involving fine-tuning SlovakBERT model for our task, we achieved average accuracy of 77.2% with a standard deviation of 0.012, representing an increase of 10% from the baseline model’s accuracy.
Fine-tuning banking-tailored BERT on translated dataset showcased the final accuracy slightly under 70%, which outperforms the baseline model, however it does not surpass the performance of fine-tuned SlovakBERT model.
Subsequently, we experimented with pre-trained (but not fine-tuned with our data) generative LLMs for our task. While these models showed promising capabilities, their performance was inferior to that of the SlovakBERT fined-tuned for our specific task. Therefore, we proceeded to fine-tune these models, namely Gemma 7b instruct and Llama3 8b instruct. Gemma 7b instruct from Llama3 8b instruct.
The fine-tuned Gemma 7b instruct 7b instruct models demonstrated a final accuracy comparable to the banking-tailored BERT, while fine-tuned Llama3 8b instruct performance was slightly worse than the SlovakBERT fined-tuned. Despite extensive efforts to find the configuration surpassing the capabilities of the SlovakBERT model, these attemps were unsuccessful, establishing the SlovakBERT model as our benchmark for performance.
All results are displayed in Table 1including the baseline proprietary model and a closed-source model for comparison.
Table 1: Percentage comparison of models’ in-scope accuracy and out-of-scope false positive rate.
Conclusion
The goal of this study was to find an approach leveraging a pre-trained language model (fine-tuned or not) as a backbone for chatbot for banking industry. The data provided for the study consisted of pairs of text and intent, where the text represents user’s (customer’s) query and the intent represents the triggered intent.
Several language models were experimented with, including SlovakBERT, banking-tailored BERT and generative models Gemma 7b instruct from Llama3 8b instructAfter experimentations with the dataset, fine-tuning configurations and prompt engineering; fine-tuning SlovakBERT emerged as the best approach yielding final accuracy slightly above 77%, which represents a 10% increase from the baseline’s models accuracy, demonstrating its suitability for our task.
In conclusion, our study highlights the efficacy of fine-tuning pre-trained language models for developing a robust chatbot with accurate intent classification. Moving forward, leveraging these insights will be crucial for further enhancing performance and usability in real-world banking applications.
Research results were obtained with the support of the Slovak National competence centre for HPC, the EuroCC 2 project and Slovak National Supercomputing Centre under grant agreement 101101903-EuroCC 2-DIGITAL-EUROHPC-JU-2022-NCC-01.
References:
[1] AI@Meta. Llama 3 model card. 2024. URL: https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md.
[2] Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey, 2024. arXiv:2403.14608.
[3] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. CoRR, abs/2106.09685, 2021. URL: https://arxiv.org/abs/2106.09685, arXiv:2106.09685.
[4] Soham Parikh, Quaizar Vohra, Prashil Tumbade, and Mitul Tiwari. Exploring zero and fewshot techniques for intent classification, 2023. URL: https://arxiv.org/abs/2305.07157, arXiv:2305.07157.
[5] Matúš Pikuliak, Štefan Grivalský, Martin Konôpka, Miroslav Blšták, Martin Tamajka, Viktor Bachratý, Marián Šimko, Pavol Balážik, Michal Trnka, and Filip Uhlárik. Slovakbert: Slovak masked language model. CoRR, abs/2109.15254, 2021. URL: https://arxiv.org/abs/2109.15254, arXiv:2109.15254.
[6] Gemma Team, Thomas Mesnard, and Cassidy Hardin et al. Gemma: Open models based on gemini research and technology, 2024. arXiv:2403.08295.
Authors
Bibiána Lajčinová – Slovak National Supercomputing Centre Patrik Valábek – Slovak National Supercomputing Centre, ) Institute of Information Engineering, Automation, and Mathematics, Slovak University of Technology in Bratislava Michal Spišiak – nettle, s.r.o., Bratislava, Slovakia
HPC webinar for SMEs: Examples of real use of HPC in Poland, the Czech Republic and Slovakia
An informative webinar was held on September 4, highlighting the potential of high-performance computing through real-life success stories and engaging projects implemented with the support of the National Competence Centers for HPC. In addition to examples implemented in the Slovak NCC, the webinar also presented the expertise and experience of neighboring competence centers in the Czech Republic and Poland.
Michal Pitoňák shared experiences from four successful HPC use cases, including the transfer and optimization of CFD computational workflows in the HPC environment, anomaly detection in time series to prevent gambling using deep learning, entity identification for address extraction from transcribed interviews using synthetic data, and measurement of structural parameters of capsules using AI and ML techniques. Tomáš Karásek presented examples of using artificial intelligence to solve engineering problems focused on energy and transportation. Szymon Mazurek introduced the SpeakLeash initiative, a community-driven project to develop a national large language model (LLM) ecosystem in Poland.
ARE YOU AN ENTREPRENEUR? HOW DO YOU DISCOVER THAT YOUR COMPANY IS UNDER CYBER ATTACK?
In today's digital era, when technology has become an essential part of business, cyber attacks are becoming an alarming reality for businesses of all sizes. With the increasing number of threats and the sophistication of attacks, it is imperative that companies invest in employee training and securing their systems.
As the number of digital devices and online services increases, so does the risk of cyber attacks, which can have serious consequences for individuals and organizations. Prevention and early detection are key to protecting sensitive data and reducing the risk of financial losses. Various forms of threats such as phishing, ransomware and DDoS attacks are becoming increasingly sophisticated and require a proactive approach to data protection.
THE MOST COMMON CYBER ATTACKS
Cyber attacks usually take place in several stages. The first is preparation and reconnaissance, where attackers gather information about the target. "It can be an analysis of public profiles on social networks, company websites or finding out technical specifications and systems. After collecting the necessary information, the attackers try to gain access to the company's systems. This can include phishing emails that contain malicious links or attachments, but also exploiting vulnerabilities in software. If attackers have access, they start by stealing data, installing malware, or directly attacking servers. In the case of ransomware, the data is encrypted and the attackers demand a ransom," explains Ondrej Kreheľ, co-founder of Conference®, ktorá sa venuje organizovaniu konferencií o kybernetickej bezpečnosti.
DDoS attacks are aimed at overloading servers and networks, causing service outages. They can result in lost productivity and financial losses for organizations.
HOW TO RECOGNIZE AND DETECT A CYBER ATTACK
Attackers are very clever and persistent, so it is crucial for businesses to have mechanisms in place to detect and prevent cyber threats. “Employees should be regularly trained in cyber security to recognize phishing emails and other fraudulent techniques. Network activity should also be monitored and analyzed. Implementing systems to monitor network traffic can help identify unusual activity that could indicate an attempted attack. Regular updates and backups will also help. Keeping software and systems up-to-date and regularly backing up data are basic steps to protect against cyber attacks," says Ondrej Kreheľ, a top cyber security expert who works in New York.
BLACKMAIL AND RANSOM IS NOT A TABOO EVEN IN SLOVAKIA The theft or encryption of sensitive company data and the subsequent request for a ransom is nothing new in Slovakia either. "It also happens to Slovak companies, it also involves millions of dollars for restoring systems and returning advances so that the company can continue. So the question is not whether it will ever happen to you, but when you will become a victim of a cyber attack," says O. Kreheľ. He also reminds that it is also important to develop an incident response plan, which can help companies quickly respond to attacks and minimize their impact.
THE CONFERENCE OFFERS A WIDE RANGE OF EXPERTS
Cybersecurity is a dynamic and ever-evolving process, and for entrepreneurs and businesses, it is essential to address it. Lectures by experts and trainings with the best in the field are offered by the Qubit Conference,® which takes place on November 13-14, 2024 in the Chopok Wellness Hotel in Jasná.
Devana: Call for Standard HPC access projects 3/24
Výpočtové stredisko SAV a Národné superpočítačové centrum otvarujú druhú tohtoročnú Call for Projects for Standard Access to HPC 3/24. Projects are possible continuously, while there are 3 closing dates as standard during the year, after which the evaluation will take place until the submitted applications. It is possible to apply for access through the register.nscc.sk user portal register.nscc.sk .
Standard access to high-performance computing resources is open to all areas of science and research, especially for larger-scale projects. These projects should demonstrate excellence in the respective fields and a clear potential to bring innovative solutions to current social and technological challenges. In the application, it is necessary to demonstrate the efficiency and scalability of the proposed calculation strategies and methods in the HPC environment. The necessary data on the performance and parameters of the considered algorithms and applications can be obtained within the Testing Access.
Allocations are awarded for one (1) year with the option to apply for extension, if necessary. Access is free of charge, provided that all requirements defined in the Terms of reference are met. Submitted projects are evaluated from a technical point of view by the internal team of CC SAS and SK NSCC, and the quality of the scientific and research part is always evaluated by two independent external reviewers.
Call opening date: 2.9.2024 Call closing date: 1.10. 2024, 17:00 CET Communication of allocation decision: Up to 2 weeks from Call closing. Start of the allocation perion for awarded projects: no latter than 15.10.2024
Eligible Researchers Scientists and researchers from Slovak public universities and the Slovak Academy of Sciences, as well as from public and state administration organizations and private enterprises registered in the Slovak Republic, can apply for standard access to HPC. Access is provided exclusively for civil and non-commercial open-science research and development. Interested parties from private companies should first contact the National Competence Centre for HPC.
Final report within 2 months from the end of the project.
Peer-review and other publications in domestic and foreign scientific periodicals with acknowledgments in the pre-defined wording, reported through the user portal.
Active participation in the Slovak HPC conference organized by the coordinator of this call (poster, other contribution).
Participation in dissemination activities of the coordinator (interview, article in the HPC magazine, etc.).