
Identifikácia entít pre extrakciu adries z transkriptovaných rozhovorov s využitím syntetických dát
Podniky vynakladajú vel’ké množstvo úsilia a finančných prostriedkov na komunikáciu s klientmi. Zvyčajne je ciel’om informácie klientom poskytnúť’, niekedy je však naopak potrebné informácie vyžiadať’ (napr. miesto bydliska). Na riešenie tejto požiadavky sa vynakladá značné úsilie, napríklad vývojom chat- a voicebotov, ktoré na jednej strane slúžia na poskytovanie informácií klientom, ale možno ich využiť’ aj na kontaktovanie klienta so žiadosťou o poskytnutie informácií. Konkrétnym príkladom z reálneho života je kontaktovanie klienta prostredníctvom textovej správy alebo telefonicky s cieľom aktualizovať’ jeho kontaktnú adresu. Keďže adresa klienta sa mohla časom zmeniť, podnik potrebuje priebežne aktualizovať tieto informácie vo svojej internej databáze klientov.

Pri vyžiadaní takýchto informácií prostredníctvom ”nových” kanálov, akými sú chat- alebo voiceboty, je dôležité overiť’ správnosť’ a formát adresy. V takýchto prípadoch informácie o adrese zvyčajne pochádzajú z voľného textového vstupu, alebo ako transkript (prepis) hovorenej reči do textu. Takéto vstupy môžu obsahovať’ značne množstvo ”šumu” alebo odchýlky voči požadovanému formátu adresy. Na overenie formátu a platnosti adresy je potrebné odfiltrovať’ šum a extrahovať’ zodpovedajúce entity, ktoré tvoria skutočnú, t.j. presnú adresu. Tento proces extrakcie entít zo vstupného textu je označovaný ako rozpoznávanie pomenovaných entít (NER, z angl. ”Named-Entity Recognition”). V našom konkrétnom prípade ide o tieto entity: názov obce, názov ulice, číslo domu a poštové smerovacie číslo. Cieľom tohto reportu je opísať’ vývoj, implementáciu a posúdenie kvality systému NER na extrakciu spomenutých informácií.
POPIS PROBLÉMU
Táto štúdia je výsledkom spoločného úsilia Národného kompetenčného centra pre vysokovýkonné počítanie a spoločnosti nettle, s.r.o., ktorá je slovenským start-upom zameraným na spracovanie prirodzeného jazyka, chatboty a voiceboty. Cieľom bolo vyvinúť’ vysoko presný a spoľahlivý NER model na extrakciu adries, ktorého vstupom je voľný text, ako aj transkript reči do textu. Výsledný NER model predstavuje dôležitý prvok pre vývoj reálnych systémov starostlivosti o zákazníkov, ktorý sa dá využiť’ všade, kde je nutné extrahovanie adresy.
Výzvou tejto štúdie bolo spracovanie dát, ktoré boli dostupné výlučne v slovenskom jazyku. Z tohto dôvodu bol výber základného modelu veľmi obmedzený. Aktuálne je k dispozícii niekoľko verejne dostupných NER modelov pre slovensky jazyk. Tieto modely sú založené na predtrénovanom univerzálnom modeli SlovakBERT [1]. Bohužiaľ’, všetky tieto modely podporujú len niekoľko typov entít, pričom podpora entít relevantných pre extrakciu adries chýba. Priame využitie populárnych veľkých jazykových modelov (LLM, z angl. ”Large Language Models”), ako je GPT, prostredníctvom cloudových rozhraní (API) neprichádza v našom prípade do úvahy, primárne z dôvodov ochrany osobných údajov a časových oneskorení.
Navrhovaným riešením je doladenie (z angl. ”fine-tuning”) modelu SlovakBERT pre NER. Úloha NER je v našom prípade klasifikačná úloha na úrovni tokenov. Cieľom je dosiahnuť’ dostatočnú presnosť’ v rozpoznávaní entít s malým počtom dostupných reálnych pozorovaní. V časti 2.1 opisujeme náš dátový súbor, vrátane procesu tvorby týchto dát. Výrazný nedostatok dostupných, reálnych pozorovaní nás prinútil vytvoriť’ ”syntetické dáta”. V časti 2.2 navrhujeme úpravy SlovakBERT-u s cieľom natrénovať’ a doladiť’ ho pre našu úlohu. V časti 2.3 skúmame iteračné zlepšenia nášho prı́stupu generovania syntetických dát. Záverom, v časti 3, uvádzame výsledky trénovania a diskutujeme výkonnosť’ modelu.
DÁTA
K dispozícii bolo iba 69 zaznamenaných, reálnych vstupov. Všetky tieto vstupy boli navyše značne ovplyvnené šumom, napr. prirodzeným váhaním v reči, chybami pri prepise reči a pod. Preto boli tieto dáta použité výlučne na testovanie. V tabuľke 1 sú uvedené dva príklady zo zhromaždeného súboru dát.
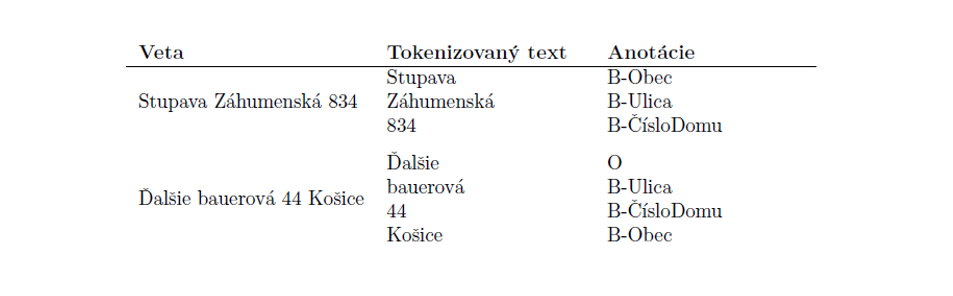
Vytváranie syntetického súboru trénovacích dát sa ukázalo ako jediná možnost’ riešenia problému nedostatku pozorovaní. Inšpirovaní 69 reálnymi príkladmi sme pomocou API do OpenAI vygenerovali množstvo podobných, reálne vyzerajúcich príkladov. Na anotovanie vygenerovaného súboru dát sa použila anotačná schéma BIO [2]. Táto schéma, často používaná v NLP na anotovanie tokenov, označuje v sekvencii začiatok (beginning – B), vnútro (inside – I) alebo ”vonkajšok” (outside – O) entít. Používame 9 anotácií: O, B-Ulica, I-Ulica, B-ČísloDomu, I ČísloDomu, B-Obec, I-Obec, B-PSČ, I-PSČ.
Údaje boli generované vo viacerých iteráciách, vid’. časť’ 2.3. Konečný súbor trénovacích dát pozostával z viac ako 104 pozorovaní. Na generovanie bolo použité GPT-3.5-turbo API. Keďže generovanie textu prostredníctvom tohto API je obmedzené počtom tokenov – ako generovaných, tak aj tokenov v prompte –, nebolo možné v rámci promptov použiť’ kompletný zoznam všetkých existujúcich slovenských názvov ulíc a obcí. Preto boli dáta generované so zástupnými znakmi názov ulice a názov obce, ktoré sa následne nahradili náhodne vybranými názvami ulíc a obcí zo zoznamov názvov ulíc, resp. obcí. Kompletný zoznam slovenských názvov ulíc a obcí bol získaný z webových stránok Ministerstva vnútra Slovenskej republiky [3].
Pomocou generatívneho algoritmu OpenAI, dostupného cez API, sa nám podarilo dosiahnuť’ organické vety bez potreby ručného generovania dát, čo výrazne urýchlilo prácu. Použitie tohto prístupu však neprebehlo úplne bez problémov. Vo vygenerovanom súbore sa vyskytovalo mnoho chýb, boli to hlavne nesprávne anotácie, ktoré bolo potrebné ručne opraviť’. Vygenerovaný súbor bol rozdelený tak, že 80% dát bolo použitých na trénovanie modelu, 15% na validáciu a 5% ako syntetické testovacie dáta, aby bolo možné porovnať’ výkonnosť’ modelu na skutočných dátach s výkonom na umelých testovacích dátach.
VÝVOJ A TRÉNOVANIE MODELOV
V práci boli boli použité a porovnané dva predtrénované, všeobecné modely pre slovenský jazyk: SlovakBERT [1] a destilovaná verzia tohto modelu [4]. V tomto texte označujeme destilovanú verziu ako DistilSlovakBERT. SlovakBERT je open source predtrénovaný model slovenského jazyka, ktorý využíva maskované modelovanie jazyka (MLM, z angl. ”Masked Language Modeling”). Bol natrénovaný na všeobecnom slovenskom webovom korpuse, ale dá sa l’ahko prispôsobit’ na riešenie nových úloh [1]. Dis-tilSlovakBERT je predtrénovaný model získaný z modelu SlovakBERT metódou nazývanou ”destilácia znalostí”, ktorá výrazne zmenšuje vel’kost’ modelu pri zachovaní (až 97%) jeho schopností porozumiet’ jazyku.
Oba modely boli upravané pridaním vrstvy klasifikácie, čím sa v oboch prípadoch získali modely vhodné pre úlohy NER. Posledná klasifikačná vrstva pozostáva z 9 neurónov zodpovedajúcich 9 anotáciám entít, t.j. 4 časti adresy a každá je reprezentovaná dvoma anotáciami – začiatok (B) a vnútro (I) každej entity a jedna anotácia je pre neprítomnosť akejkoľvek entity (O). Počet parametrov pre každý model a jeho zložky sú zhrnuté v tabuľke 2.

Trénovanie modelov sa ukázalo byt’ značne náchylné na preučenie. Na riešenie tohto problému a dalšie zlepšenie procesu trénovania bolo použíté lineárne zmenšovanie parametru rýchlosti učenia, regularizačná stratégiu ”weight decay” a niektoré d’alšie stratégie ladenia hyperparametrov.
Na trénovanie modelov boli využité výpočtové prostriedky HPC systému Devana, ktorý prevádzkuje Výpočtové stredisko Centra spoločných činností SAV, konkrétne s využitím akcelerovaného uzla s 1 grafickou kartou (GPU) NVidia A100. Na pohodlnejšiu analýzu a ladenie bolo využívané interaktívne prostredie OpenOnDemand, ktoré umožňuje používatel’om vzdialený webový prístup k superpočítaču.
Proces trénovania vyžadoval iba 10 − 20 epoch na natrénovanie pre oba modely. Pri použití spomenutých HPC prostriedkov bol čas trénovania jednej epochy v priemere 20 sekúnd pre 9492 vzoriek v trénovanom súbore dát pre SlovakBERT a 12 sekúnd pre DistilSlovakBERT. Inferencia na 69 vzorkách trvá 0, 64 sekundy pre SlovakBERT a 0, 37 sekundy pre DistilSlovakBERT, čo dokazuje dostatočnú efektivitu pre použitie týchto modelov v NLP aplikáciách v reálnom čase.
ITERATÍVNE VYLEPŠENIA
Hoci sme mali k dispozícii len 69 reálnych pozorovaní, ich komplexnost’ bola pomerne náročná na simulovanie v generovaných dátach. Generovaný súbor dát bol vytvorený pomocou viacerých promptov, výsledkom čoho bolo 11,306 viet, ktoré pripomínali človekom generovaný text. Získanie finalného riešenia pozostávalo z niekol’kých iterácií, pričom každú iteráciu možno rozdeliť na viaceré kroky: generovanie dát, trénovanie modelu, vizualizácia chýb predikcie na reálnych a umelých testovacích dátach a ich analýza. Týmto spôsobom boli identifikované vzory, ktoré model nedokázal rozpoznat’. Na základe týchto poznatkov boli vygenerované nové dáta, ktoré sa riadili týmito novoidentifikovanými vzormi. Dáta dopĺňané v iteráciách boli generované pomocou promptov uvedených v tabul’ke 3. Pomocou každého novorozšíreného súboru dát boli natrénované oba modely, pričom presnost’ modelu Slovak-BERT vždy prevyšovala presnost’ modelu DistilSlovakBERT. Preto bol d’alej využívaný ako základný model už iba SlovakBERT.
Výsledky
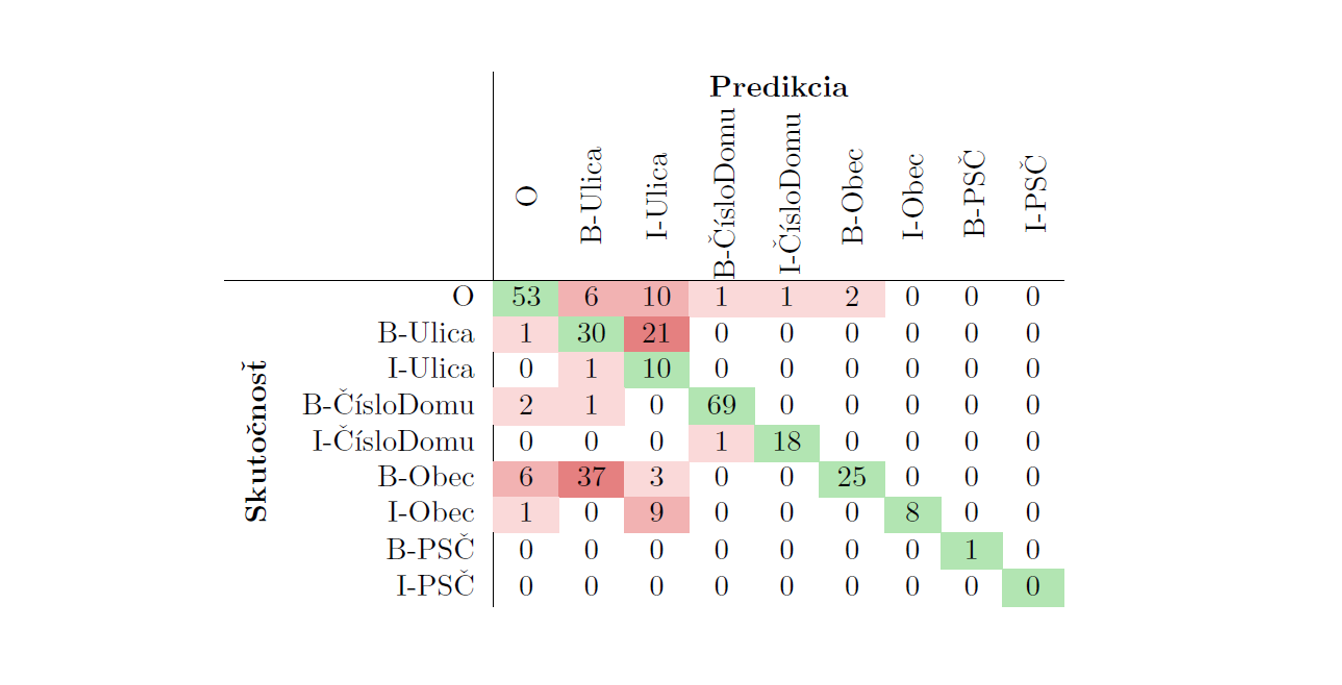
Matica zámen (z angl. ”Confusion Matrix”) zodpovedajúca výsledkom modelu natrénovaného v Iterácii 1 (pozri Tabul’ka 3)—je zobrazená v Tabul’ke 4. Tento model dokázal správne rozpoznat’ iba 67, 51% entít v testovacom súbore údajov. Podrobné preskúmanie chýb predikcie ukázalo, že súbor trénovacích dát nereprezentuje dostatočne dobre reálne pozorovania a je potrebné generovat’ viac reprezentatívnejších údajov. V tabul’ke 4 je zrejmé, že najčastejšou chybou bola identifikácia obce ako ulice a dochádzalo k tomu v prípadoch, ked’ sa názov obce objavil pred názvom ulice v adrese. Výsledkom bolo generovanie dát pomocou iterácie 2 a iterácie 3.

Ciel’om bolo dosiahnut’ viac ako 90% presnost’ na reálnych testovacích dátach. Presnost’ predikcie modelu sa so systematickým generovaním údajov neustále zvyšovala. Finálne bol celý súbor údajov zduplikovaný tak, že duplicity reflektovali text s použitím len malých písmen, nakol’ko využitý predtrénovaný model je citlivý na malé a vel’ké písmená a niektoré testovacie pozorovania obsahovali názvy ulíc a obcí s malými písmenami. Vd’aka tomu sa model stal robustnejším voči forme, v ktorej dostáva vstup, a dosiahol konečnú presnost’ 93,06%. Matica zámen najlepšieho (finálneho) modelu je zobrazená v Tabul’ke 5.
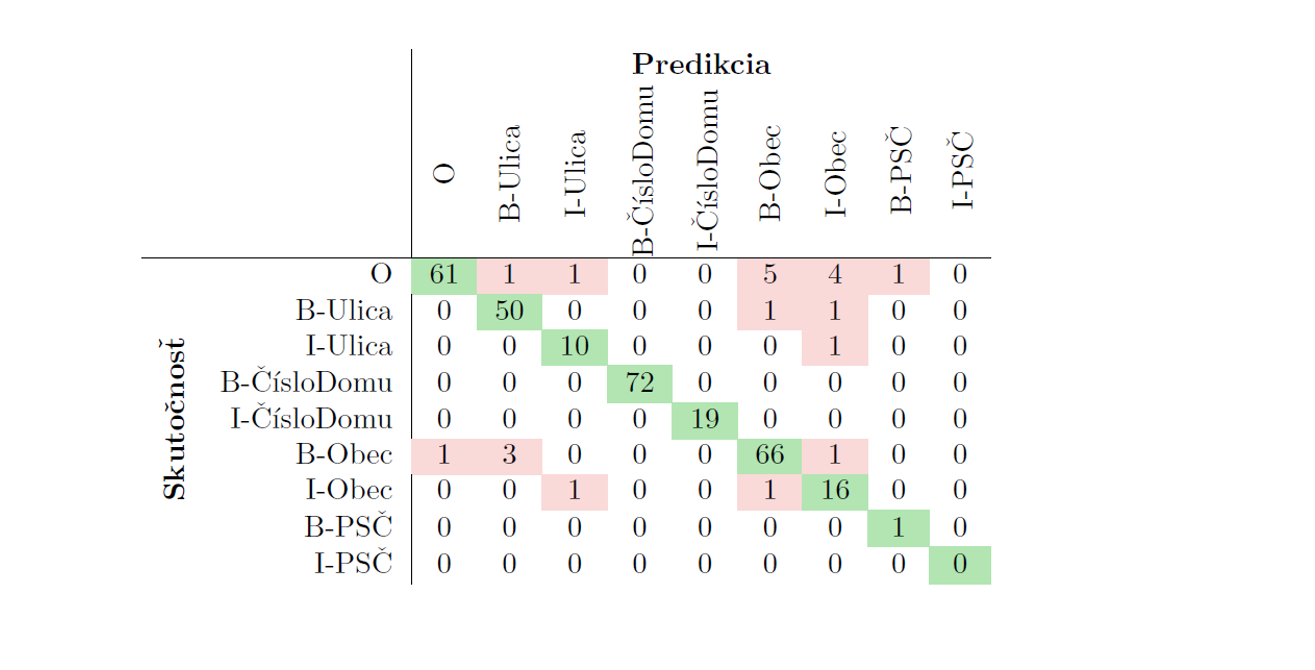
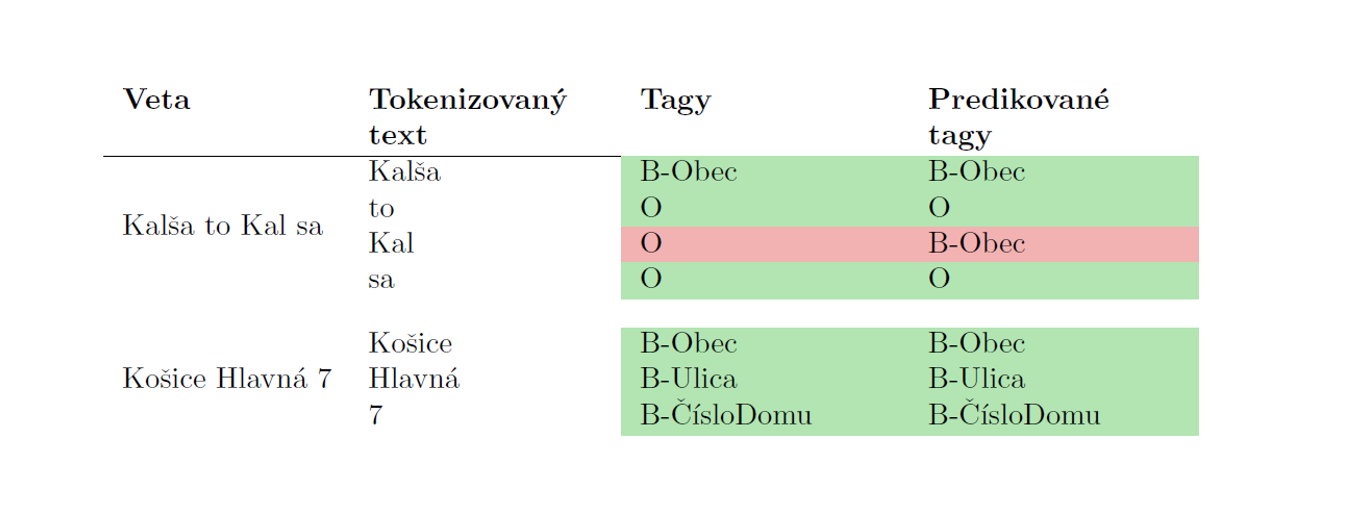
V predikciách sa stále vyskytujú niektoré chyby; najmä tokeny, ktoré majú byt’ identifikované ako O, sú občas nesprávne klasifikované ako Obec. Týmto problémom sme sa d’alej nezaoberali, pretože sa vyskytuje pri slovách, ktoré sa môžu podobat’ na časti názvov entít, ale v skutočnosti nepredstavujú samotné entity. Príklad je zobrazený v Tabul’ke 6.
ZÁVER
V tejto štúdii bol natrénovaný NER model postavený na predtrénovanom LLM modeli SlovakBERT. Model bol natrénovaný výlučne na umelo vygenerovanom súbore dát. Finálne syntentické trénovacie dáta boli reprezentatívne a kvalitné, vd’aka ich iteratívnemu rozširovaniu. Spolu s dolad’ovaním hyperparametrov tento iteratívny prístup umožnuje dosiahnut’ predikčnú presnost’ na reálnom dátovom súbore, presahujúcu 90%. Prezentovaný prístup naznačuje vysoký potenciál používania výlučne synteticky generovaných dát a to najmä v prípadoch, ked’ množstvo reálnych údajov nie je dostatočné na trénovanie.
Získaný model je možné využit’ v reálnych aplikáciách slúžiacich na extrakciu a overenie správnosti adries, získaných mechanizmami prevodu reči na text. V prípade, že je k dispozícii väčší súbor reálnych dát, odporúčame model pretrénovat’ a prípadne aj rozšírit’ syntetický súbor dát o d’alšie generované údaje, pretože existujúci súbor nemusí reprezentovat’ potenciálne nové vzory v týchto nových, reálnych dátach.
Model je dostupný na https://huggingface.co/nettle-ai/slovakbert-address-ner
POĎAKOVANIE
Výskum bol realizovaný s podporou Národného kompetenčného centra pre HPC, projektu EuroCC 2 a Národného Superpočítačového Centra na základe dohody o grante 101101903-EuroCC 2-DIGITAL-EUROHPC-JU-2022-NCC-01. Výskum (alebo jeho čast’) bol realizovaný s využitím výpočtovej infraštruktúry obstaranej v projekte Národné kompetenčné centrum pre vysokovýkonné počítanie (kód projektu: 311070AKF2) financovaného z Európskeho fondu regionálneho rozvoja, Štrukturálnych fondov EÚ Informatizácia spoločnosti, operačného programu Integrovaná infraštruktúra 2014-2020.
AUTORI
Bibiána Lajčinová – Národné superpočítačové centrum
Patrik Valábek – Národné superpočítačové centrum, Ústav informatizácie, automatizácie a matematiky, Slovenská technická univerzita v Bratislave
Michal Spišiak – nettle, s. r. o.
Plná verzia článku SK
Plná verzia článku EN
Zdroje:
[1] Matús Pikuliak, Stefan Grivalsky, Martin Konopka, Miroslav Blsták, Martin Tamajka, Viktor Bachratý, Marián Simko, Pavol Balázik, Michal Trnka, and Filip Uhlárik. Slovakbert: Slovak masked language model. CoRR, abs/2109.15254, 2021.
[2] Lance Ramshaw and Mitch Marcus. Text chunking using transformation-based learning. In Third Workshop on Very Large Corpora, 1995.
[3] Ministerstvo vnútra Slovenskej republiky. Register adries. https://data.gov.sk/dataset/register-adries-register-ulic. Accessed: August 21, 2023.
[4] Ivan Agarský. Hugging face model hub. https://huggingface.co/crabz/distil-slovakbert, 2022. Accessed: September 15, 2023.
 Umelá inteligencia a superpočítač ako nová zbraň proti ekologickým haváriám 26 mar - Slovenskí vedci z Nitry učia stroje predvídať poruchy v priemysle skôr, než stihnú napáchať škody. Vďaka spolupráci s európskym superpočítačom LUMI vyvinuli digitálneho „strážcu“, ktorý dokáže s vysokou presnosťou odhaliť úniky v potrubiach alebo chyby vo výrobe, čím chráni našu prírodu aj peňaženky podnikov.
Umelá inteligencia a superpočítač ako nová zbraň proti ekologickým haváriám 26 mar - Slovenskí vedci z Nitry učia stroje predvídať poruchy v priemysle skôr, než stihnú napáchať škody. Vďaka spolupráci s európskym superpočítačom LUMI vyvinuli digitálneho „strážcu“, ktorý dokáže s vysokou presnosťou odhaliť úniky v potrubiach alebo chyby vo výrobe, čím chráni našu prírodu aj peňaženky podnikov. Slovenský recept na férové hry a spokojnejších hráčov 25 mar - Hráte sa na mobile a máte pocit, že vám hra nerozumie? Slovenskí experti z Nitry využili jeden z najvýkonnejších superpočítačov v Európe, aby to zmenili. Vďaka talianskemu obrovi menom Leonardo prišli na to, ako čítať medzi riadkami hráčskeho správania a urobiť herný zážitok osobnejším a férovejším.
Slovenský recept na férové hry a spokojnejších hráčov 25 mar - Hráte sa na mobile a máte pocit, že vám hra nerozumie? Slovenskí experti z Nitry využili jeden z najvýkonnejších superpočítačov v Európe, aby to zmenili. Vďaka talianskemu obrovi menom Leonardo prišli na to, ako čítať medzi riadkami hráčskeho správania a urobiť herný zážitok osobnejším a férovejším. Mestské budovy sa prebúdzajú: Slovenská AI dáva druhú šancu nevyužitým priestorom 4 mar - Mestá sú živé organizmy, ktoré sa neustále menia. Mnohí z nás však v susedstve denne míňajú tiché svedectvá minulosti – prázdne školy, nevyužívané úrady či chátrajúce verejné budovy. Často si kladieme otázky: „Prečo je to zatvorené?“ „Nemohol by tu byť radšej denný stacionár, škôlka alebo kultúrne centrum?“
Mestské budovy sa prebúdzajú: Slovenská AI dáva druhú šancu nevyužitým priestorom 4 mar - Mestá sú živé organizmy, ktoré sa neustále menia. Mnohí z nás však v susedstve denne míňajú tiché svedectvá minulosti – prázdne školy, nevyužívané úrady či chátrajúce verejné budovy. Často si kladieme otázky: „Prečo je to zatvorené?“ „Nemohol by tu byť radšej denný stacionár, škôlka alebo kultúrne centrum?“