Operačné systémy v multiprocesorových klastroch
10. novembra 2021 sa uskutočnila už štvrtá prednáška série Superpočítanie vo vede. Tentokrát sme privítali Dr. Dušana Bernáta z Fakulty matematiky, fyziky a informatiky Univerzity Komenského so zaujímavou prednáškou na tému Operačné systémy v multiprocesorových klastroch.

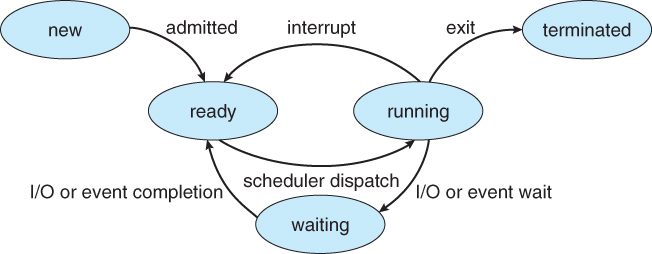
Účastníci získali prehľad o základných pojmoch a definíciách, ako operačný systém umožňuje a zabezpečuje prístup aplikácií a procesov k prostriedkom a ako tieto prostriedky spravuje. Dozvedeli sme sa viac o stavoch a zmenách stavu jednotlivých procesov. Zaujímavé boli aj informácie o tom, ako vyzerá politika a réžia plánovača (scheduler), ktorý prístup na CPU procesom prideľuje.
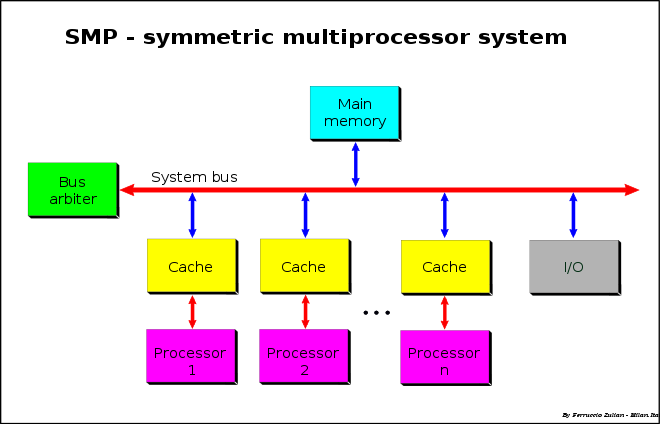
Z hľadiska vysokovýkonných výpočtových prostriedkov nás zaujíma, ako funguje OS v prostredí s mnohými procesormi. Zvyšovanie počtu procesorov je prirodzenou odpoveďou na rýchly nárast požiadaviek aplikácií a súčasne limitov zvyšovania výkonu jediného CPU. Operačný systém teda môže úlohy rozdeľovať medzi viaceré fyzické procesory (alebo jadrá), pričom tieto procesy sú nezávislé a môžu bežať súbežne. Programátori môžu využiť výhody viacerých procesorov a svoje úlohy rozdeliť na viacero súbežných podúloh. Tieto už ale nie sú nezávislé a väčšinou je potrebné, aby medzi sebou navzájom komunikovali. Jedna úloha – proces môže mať teda viacero samostatných tokov riadenia, ktoré nazývame vlákna (threads) a ktoré zdieľajú väčšinu prostriedkov tohto procesu, vrátane pamäte. Z pohľadu architektúry to môže vyzerať ako na obrázku ilustrujúcom schému symetrického multiprocesorového systému (Obr. 2), kde je jedna pamäť zdieľaná viacerými rovnocennými procesormi (architektúra UMA – Uniform Memory Access). Tu je potrebné ošetriť synchronizáciu prístupu k tejto spoločnej pamäti, čo je možné urobiť viacerými spôsobmi. Prístup SMP – symetrického multiprocesingu má však nevýhody ako zlá škálovateľnosť, čakanie pri synchronizácii, tzv. cache trashing.
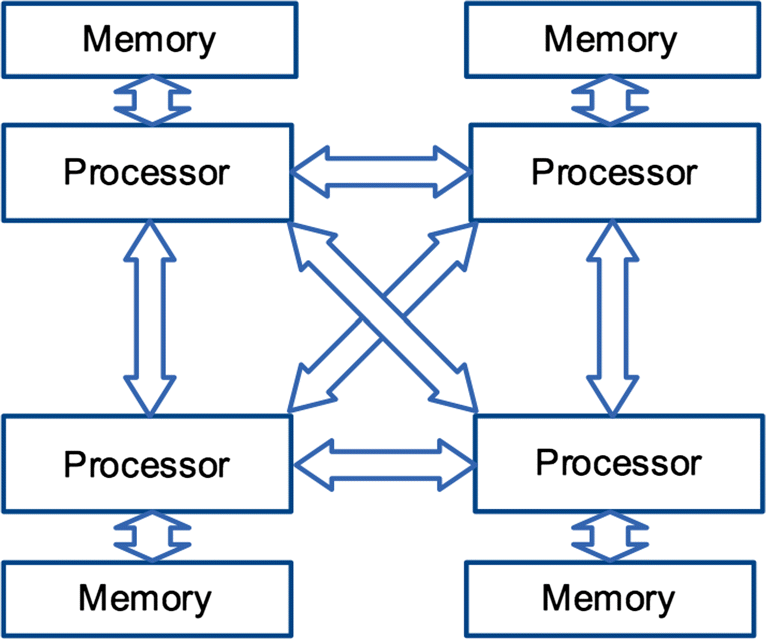
Ak fyzickú pamäť rozdelíme na viaceré moduly, dosiahneme menšie zaťaženie zbernice, pretože procesory budú najviac využívať vlastnú lokálnu pamäť. Tento prístup poznáme ako NUMA – Non-Uniform Memory Access. Tu je najvýhodnejšie, ak OS alokuje úlohe pamäť pre dáta čo najbližšie k procesoru, na ktorom úloha beží. Na obrázku vidíme príklad prepojenia 4 procesorov:
Prednáška pokryla aj tému správy pamäte, virtuálnu pamäť a jej alokáciu – vrátane konceptu overcommit a tému súborového systému a jeho hierarchie.
Operačné systémy a ich fungovanie v HPC prostredí by si určite zaslúžili aj viac priestoru, ako náš formát môže poskytnúť. Ak vás téma zaujala, na Fakulte matematiky, fyziky a informatiky UK na túto tému prednáša práve Dr. Dušan Bernát – a ak ste našu prednášku nestihli, môžete si ju pozrieť na Facebookovom profile alebo YouTube Centra spoločných činností SAV.
Harmonogram prednášok:
- 23. novembra o 17:00 – Krátky návod ako paralelizovať program
Jaroslav Suchánek (Biomedicínske centrum SAV) - 7. decembra o 17:00 – Federatívne distribuované počítanie
Ladislav Hluchý (Ústav informatiky SAV)




 Nový recept na skrotenie slnečnej energie 11 jún - Umelá inteligencia v spojení s čistou fyzikou dokáže predpovedať silu slnečného žiarenia rýchlejšie a lacnejšie než kedykoľvek predtým
Nový recept na skrotenie slnečnej energie 11 jún - Umelá inteligencia v spojení s čistou fyzikou dokáže predpovedať silu slnečného žiarenia rýchlejšie a lacnejšie než kedykoľvek predtým