
Use case: Prenos a optimalizácia pracovného toku CFD výpočtov v HPC prostredí
Autori: Ján Škoviera (Národné kompetenčné centrum pre HPC), Sylvain Suzan (Shark Aero)
Spoločnosť Shark Aero navrhuje a vyrába ultraľahké športové lietadlá s dvojmiestnym tandemovým kokpitom. Na vývoj dizajnu používajú populárny open-source softvérový balík openFOAM [1], konkrétne CFD simulácie (Computational Fluid Dynamics), využívajú metódu konečných prvkov (Finite elements method – FEM). Po vytvorení modelu pomocou softvéru Computer-Aided Design (CAD) sa model rozdelí na samostatné bunky, tzv. sieť (angl. mesh). Presnosť simulácie silne závisí od hustoty siete, pričom výpočtové a pamäťové požiadavky stúpajú s treťou mocninou počtu jej vrcholov. Pre niektoré simulácie môžu byť výpočtové nároky naozaj limitujúcim faktorom, ak používateľ pracuje s bežne dostupnou výpočtovou technikou. Pokúsili sme sa preto preniesť pracovný tok simulácie do High-Performance Computing (HPC) prostredia s osobitným zameraním na preskúmanie efektívnosti paralelizácie výpočtových úloh pre daný typ modelu.

METÓDY
Pre tento projekt boli použité výpočtové uzly s 2×6 jadrami Intel Xeon L5640 @ 2,27GHz, 48 GB RAM a 2×500 GB. Všetky výpočty sa robili v štandardnom HPC prostredí s použitím systému plánovania úloh Slurm. Takéto riešenie je prijateľné pre typ výpočtových úloh, kde sa nevyžaduje odozva v reálnom čase ani okamžité spracovanie údajov. Pre CFD simulácie sme používali softvérové balíky OpenFOAM a ParaView verzie 9. Na spúšťanie výpočtov bol použitý kontajnerový softvér Singularity s ohľadom na možný budúci prenos výpočtov na iný HPC systém. Podľa očakávania, zrýchlenie výpočtov dosiahnuté len samotným transferom do HPC prostredia bolo približne 1,5x v porovnaní so štandardným notebookom.
PARALELIZÁCIA
Paralelne vykonávané výpočtové úlohy môžu zvýšiť rýchlosť celkového výpočtu využitím viacerých výpočtových jednotiek súčasne. Pre paralelizáciu úlohy takéhoto typu je potrebné rozdeliť pôvodnú sieť na domény – časti, ktoré sa budú spracovávať súbežne. Domény však potrebujú komunikovať cez procesorové okrajové podmienky, t.j. steny domény alebo plochy v mieste rozdelenia pôvodnej siete. Čím väčšia je hraničná plocha procesora, tým viac I/O operácií je potrebných na vyriešenie okrajových podmienok. Dátová komunikácia procesorových okrajových podmienok je zabezpečená protokolom MPI (distributed memory Message Passing Interface), takže rozdiel medzi jadrami CPU a rôznymi výpočtovými uzlami je od používateľa abstrahovaný. To vedie k určitým obmedzeniam efektívneho využívania mnohých paralelných procesov, pretože príliš paralelizované vykonávanie úloh môže byť v skutočnosti pomalšie kvôli úzkym miestam v komunikácii a I/O. Preto by mali byť domény vytvorené spôsobom, ktorý minimalizuje hranice procesora. Jednou z možných stratégií je rozdeliť pôvodnú sieť iba v koplanárnom smere s čo najmenšou stranou pôvodnej siete. Pri paralelizácii a definícii domén je potrebné dbať na množstvo prenášaných údajov – napríklad pri delení siete vo viacerých osiach sa vytvorí aj viac procesorových okrajových podmienok.
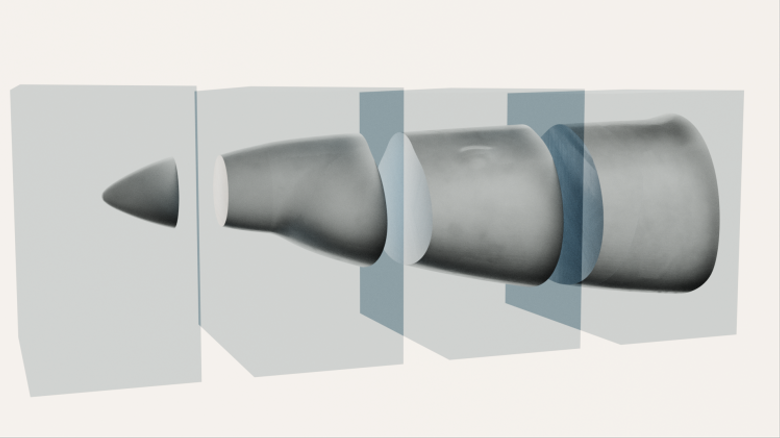
Výpočty sa robili v štyroch krokoch: generovanie siete, segmentácia siete, vnorenie modelu a simulácia CFD. Prvý krok – vytvorenie siete sme urobili pomocou utility blockMesh, nsledovala segmentácia siete pomocou utility decomposePar, vnorenie modelu pomocou programu snappyHexMesh a samotná CFD simulácia bola robená programom SimpleFoam. Výpočtovo najnáročnejší krok je snappyHexMesh. Je to pochopiteľné z toho, že kým pri CFD simulácii je potrebné vykonať výpočet niekoľkokrát pre každú hranu siete a každú iteráciu, v prípade vnorenia modelu sa vytvárajú nové vrcholy a staré sa vymazávajú na základe polohy vrcholov siete. To si vyžaduje vytvorenie „oktree“ (rozdelenie trojrozmerného priestoru jeho rekurzívnym rozdelením na osem oktantov), opakované inverzné vyhľadávanie a opätovné zaradenie do oktantov. Každý z týchto procesov je N*log(N) v najlepšom prípade a N2 v najhoršom prípade, kde N je počet vrcholov. Samotné CFD škáluje lineárne s počtom hrán, t.j. „takmer“ lineárne s N (prepojené sú len priestorovo blízke uzly). Vyvinuli sme pracovný postup, ktorý vytvára množstvo domén, ktoré môžu byť priamo paralelné s rovinou yz (x je os nosa lietadla), čo používateľovi zjednodušuje rozhodovanie. Po zahrnutí nového modelu je možné jednoducho špecifikovať počet domén a spustiť výpočet, čím sa minimalizuje ľudský zásah potrebný na paralelizáciu výpočtu.
VÝSLEDKY A ZÁVER
Relatívne zrýchlenie výpočtových procesov je určené najmä obmedzenými vstupmi/výstupmi. Ak sú výpočtové úlohy hlboko pod hranicou I/O operácií, rýchlosť je nepriamo úmerná počtu domén. Pri menej náročných výpočtoch, t.j. pri malých modeloch sa môžu procesy ľahko stať nadmerne paralelizovanými.
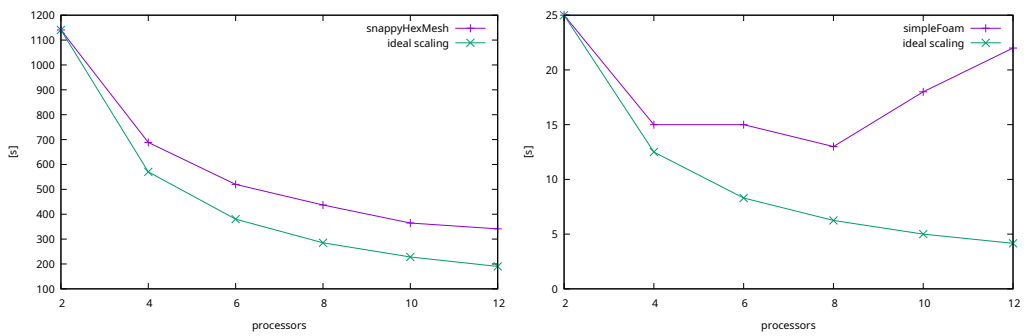
Keď je hustota siete dostatočne vysoká, čas na výpočet kroku CFD je tiež nepriamo úmerný počtu paralelných procesov. Ako je znázornené na druhej dvojici obrázkov s dvojnásobným zvýšením hustoty siete, výpočty sú pod hranicou I/O dokonca aj v CFD kroku. Aj keď je krok CFD v tomto prípade pomerne rýchly v porovnaní s procesom tvorby siete, výpočet dlhých časových intervalov by z neho mohol urobiť časovo najnáročnejší krok.
Návrh častí lietadla vyžaduje viacnásobné simulácie relatívne malých modelov za meniacich sa podmienok. Hustota siete potrebná pre tieto simulácie patrí do strednej kategórie. Pri prenose výpočtov do HPC prostredia sme museli brať do úvahy skutočné potreby koncového užívateľa z hľadiska veľkosti modelu, hustoty siete a požadovanej presnosti výsledku. Používanie HPC má niekoľko výhod:
- Koncový používateľ je nepotrebuje udržiavať svoje vlastné výpočtové kapacity.
- Aj v prípade, že by simulácie boli obmedzené na úlohy s jedným vláknom (neparalelizované), ich prenos do HPC prostredia predstavuje zrýchlenie, navyše s možnosťou použitia tzv. embarrassingly parallel prístupu.
- Pre ďalšie zefektívnenie vypočtov bol navrhnutý jednoduchý spôsob využitia paralelizácie pre tento konkrétny typ úloh. Identifikovali sme obmedzenia paralelných behov pre definovaný prípad použitia a podmienky. Celkové zvýšenie rýchlosti, ktoré bolo dosiahnuté v praktických podmienkach, je 7,3-násobné. Vo všeobecnosti je možné očakávať zrýchlenie rastúce so zložitosťou výpočtu a presnosťou/hustotou siete.

 Nový recept na skrotenie slnečnej energie 11 jún - Umelá inteligencia v spojení s čistou fyzikou dokáže predpovedať silu slnečného žiarenia rýchlejšie a lacnejšie než kedykoľvek predtým
Nový recept na skrotenie slnečnej energie 11 jún - Umelá inteligencia v spojení s čistou fyzikou dokáže predpovedať silu slnečného žiarenia rýchlejšie a lacnejšie než kedykoľvek predtým Umelá inteligencia a superpočítač ako nová zbraň proti ekologickým haváriám 26 mar - Slovenskí vedci z Nitry učia stroje predvídať poruchy v priemysle skôr, než stihnú napáchať škody. Vďaka spolupráci s európskym superpočítačom LUMI vyvinuli digitálneho „strážcu“, ktorý dokáže s vysokou presnosťou odhaliť úniky v potrubiach alebo chyby vo výrobe, čím chráni našu prírodu aj peňaženky podnikov.
Umelá inteligencia a superpočítač ako nová zbraň proti ekologickým haváriám 26 mar - Slovenskí vedci z Nitry učia stroje predvídať poruchy v priemysle skôr, než stihnú napáchať škody. Vďaka spolupráci s európskym superpočítačom LUMI vyvinuli digitálneho „strážcu“, ktorý dokáže s vysokou presnosťou odhaliť úniky v potrubiach alebo chyby vo výrobe, čím chráni našu prírodu aj peňaženky podnikov.